- 2 сентября 2020
Компилятор Glow оптимизирует нейронные сети для микроконтроллеров NXP
Область машинного обучения, а конкретнее — глубокого обучения (deep learning), развивается очень высокими темпами. Это выражается в быстром расширении рынка, особенно по мере того, как глубокое обучение перемещается на границу границы сети. Компания NXP отмечает резкий рост числа заказчиков, использующих глубокое обучение, так как инженеры всё чаще создают приложения с элементами компьютерного зрения или распознавания речи на базе технологии машинного обучения. Расширяется набор платформ и инструментов глубокого обучения, а также других средств разработки и развёртывания моделей для нейронных сетей.
Одним из таких инструментов является Glow — компилятор моделей для нейронных сетей (Neural Network — NN). Параллельно с распространением платформ глубокого обучения, таких как PyTorch, набирают популярность компиляторы для нейронных сетей, которые оптимизируют модели и помогают ускорить формирование умозаключений на целом ряде аппаратных платформ. В мае 2018 года компания Facebook представила компилятор Glow (от названия метода «graph lowering» — спуск от высокоуровневого представления графа к низкоуровневому) в рамках открытого проекта, который активно развивался в последние два года сообществом, насчитывающим более 130 участников по всему миру.
Недавно NXP объявила об официальной поддержке компилятора Glow, который обеспечивает важные преимущества в области производительности и требований к памяти для наших приборов. Компания включила компилятор Glow в свой комплект ПО для разработчиков MCUXpresso SDK, который содержит также средства квантования, простой в использовании установщик, подробную документацию и практические руководства, позволяющие разработчикам быстро перейти к работе с собственными моделями.
Гибкая функциональность Glow
Компилятор Glow для нейронных сетей с помощью графа вычислений генерирует оптимизированный машинный код в два этапа. На первом этапе он оптимизирует операторы и уровни модели с применением стандартных методов компиляции, таких как слияние ядер (kernel fusion), спуск сложных операций на простые ядра и устранение транспонирования. На втором этапе постпроцессорной (backend) компиляции компилятор Glow использует модули LLVM для оптимизации модели с учётом специфики целевого прибора. Glow поддерживает метод статической компиляции (AOT): компиляция выполняется перед исполнением кода; её результатом является объектный файл (так называемый пакет Glow — Glow bundle), который затем подключается к коду пользовательского приложения. При создании объектного файла удаётся исключить все необязательные накладные расходы, что позволяет сократить объём вычислений и расход памяти. Такой метод идеально подходит для недорогих микроконтроллеров с ограниченным объёмом памяти.
Оптимизация с учётом специфики целевого прибора
Хотя модели, скомпилированные с использованием Glow, совместимы с любым прибором NXP серии i.MX RT, в компании начали тестирование с микроконтроллера i.MX RT1060, который способен работать также с платформой TensorFlow™ — таким образом удалось провести прямое сравнение производительности. Кроме того, в тестирование включили новый микроконтроллер i.MX RT685, единственный прибор серии i.MX RT с процессором цифровой обработки сигналов, оптимизированным для нейронных сетей. В состав микроконтроллера i.MX RT1060 входит 600-МГц процессор ARM® Cortex®-M7 и память SRAM объёмом 1 МБ. Микроконтроллер i.MX RT685 содержит 600-МГц процессор цифровой обработки сигналов Cadence® Tensilica® HiFi 4 DSP и 300-МГц процессор Cortex-M33, а также 4.5 МБ встроенной памяти SRAM.
Стандартная версия Glow, опубликованная на GitHub, является аппаратно независимой и поддерживает компиляцию для основных базовых архитектур. Так, например, при кросс-компиляции пакета для ядра ARM Cortex-M7 следует использовать параметры командной строки –target=arm -mcpu=cortex-m7. Как уже упоминалось, поддержка постпроцессорного компилятора LLVM в Glow делает возможной кросс-компиляцию для различных целевых архитектур. Компания NXP применяет программную библиотеку ARM CMSIS-NN, помогающую в полной мере раскрыть потенциал ядра Cortex-M7 и подсистемы памяти прибора i.MX RT1060. Библиотека CMSIS-NN, разработанная компанией ARM для поддержки ядер ARM Cortex-M0, -M3, -M4, -M7 и -M33, реализует стандартные операции нейронных сетей, такие как свёртка (convolution), получение полносвязных (fully connected) слоёв, субдискретизация (pooling) и активация (activation). Чтобы значительно повысить производительность, достаточно использовать флаг компиляции -use-cmsis при построении квантованных пакетов. Так, например, по результатам измерений NXP на модели CIFAR-10 при использовании библиотеки CMSIS-NN для ускорения операций в нейронной сети производительность возросла почти в два раза.
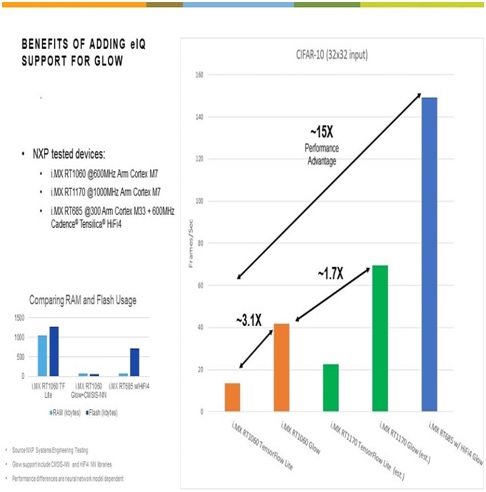
Ядро процессора HiFi 4 DSP в приборе i.MX RT685 также способно ускорить работу при выполнении широкого спектра операций в нейронной сети с использованием библиотеки для нейронных сетей (NNLib) компании Cadence в качестве другого постпроцессорного компилятора LLVM для Glow. Библиотека NNLib похожа на CMSIS-NN, однако она содержит значительно более широкий набор операторов, вручную оптимизированных для процессора HiFi 4 DSP. В том же примере с моделью CIFAR-10 этот процессор цифровой обработки сигналов продемонстрировал 25-кратный рост производительности по сравнению со стандартной реализацией на Glow.
PyTorch для встраиваемых систем
Платформа PyTorch способна экспортировать модели непосредственно в формат ONNX для компилятора Glow. Возможен альтернативный подход: поскольку многие широко известные модели были созданы в других форматах (например, TensorFlow), существует целый ряд открытых инструментов для конвертации моделей в формат ONNX. Наиболее популярными средствами преобразования форматов являются поддерживаемый корпорацией Microsoft® набор инструментов MMDNN для пользователей, работающих с различными платформами глубокого обучения, и tf2onnx, предназначенный для конвертации моделей TensorFlow в формат ONNX. Кроме того, компания NXP предложила сообществу Glow функцию, позволяющую перенести модели TensorFlow Lite непосредственно на Glow. Позже появилась возможность прямого доступа к Glow из PyTorch, благодаря чему пользователи теперь могут создавать и компилировать свои модели в одной и той же среде программирования, что помогает исключить некоторые этапы и упростить процесс компиляции.
PyTorch широко используется в центрах обработки данных крупных компаний, таких как Facebook, в связи с чем могут возникать сомнения, применима ли эта платформа для встраиваемых микроконтроллеров? Поскольку компилятор Glow теперь доступен непосредственно из среды PyTorch, стоит ли беспокоиться о том, что «PyTorch и, следовательно, Glow, не подходит для микроконтроллеров»? Если отвечать коротко, то «нет», особенно с учётом статической компиляции, реализованной в Glow.
Тем не менее, следует отметить, что сама платформа PyTorch, похоже, не ориентирована на микроконтроллеры. Этот проект развивается сообществом, и пока никто не пытался реализовать их поддержку. По понятным причинам Facebook не использует PyTorch на микроконтроллерах, однако сообщество разработчиков встраиваемого ПО в целом позитивно относится к микроконтроллерам и встраиваемым платформам. Похоже, реализация такого подхода — лишь вопрос времени благодаря растущему вниманию к PyTorch, особенно среди представителей академических и исследовательских организаций. Согласно статистике1), основное внимание на конференциях по проблемам компьютерного зрения и распознавания естественных языков уделяется PyTorch (преимущество над TensorFlow 2:1 и 3:1, соответственно), кроме того, платформа PyTorch уже стала более обсуждаемой, чем TensorFlow на конференциях по общим вопросам машинного обучения, таких как ICLR и ICML. В конечном итоге переход исследователей в промышленность будет способствовать адаптации PyTorch к условиям вычислений на границе сети.
Таким образом, PyTorch — это хороший выбор для микроконтроллеров благодаря возможности генерировать модели в формате ONNX для компиляции с помощью Glow, при этом ограничения процессорной платформы минимальны. А использование Glow в качестве расширения для PyTorch ещё больше упрощает создание пакетов. Пользователь может генерировать пакеты прямо из сценария на языке Python без предварительного создания моделей в формате ONNX. В ближайшее время компания NXP выпустит руководство по созданию и развёртыванию моделей с помощью PyTorch и Glow.
Недавно компания NXP официально объявила о поддержке Glow. Фактически, этот компилятор входит в комплект для разработчиков MCUXpresso SDK вместе с примерами проектов. Кроме того, NXP включила инструменты компиляции и квантования Glow в состав простого в использовании установщика вместе с подробной документацией и практическими руководствами, которые помогут разработчикам быстро подготовиться к созданию собственных моделей. Благодаря значительным преимуществам в области производительности и памяти данный компилятор станет настоящим подарком для разработчиков встраиваемых систем, реализующих машинное обучение с кроссоверными микроконтроллерами серии i.MX RT компании NXP.
Автор: Маркус Леви (Markus Levy), июль 2020 г.
Техническая поддержка: nxp@symmetron.ru